







[The Information-Cost-Reward Framework for robot swarm foraging]
Project: Designing Robot Swarms
Date: Nov 2017
Publication: Pitonakova, L., Crowder, R. & Bullock, S. (2018). The Information-Cost-Reward framework for understanding robot swarm foraging. Swarm Intelligence, 12(1), 71-96.


 Currently, one of the main challenges in swarm robotics is understanding how the behaviour of individual robots leads to an observed emergent collective performance. The Information-Cost-Reward (ICR) framework represents a novel approach to understanding robot swarms that perform foraging. During foraging, robots need to search for worksites in an unknown environment and either perform work on them (for example, in the case of area surveillance), or collect items from the worksites and bring them to a designated location (for example, in resource collection applications).
The ICR framework relates the way in which robots obtain and share information about where work needs to be done to the swarm’s ability to use that information to perform work efficiently, given a particular task and environment.
Currently, one of the main challenges in swarm robotics is understanding how the behaviour of individual robots leads to an observed emergent collective performance. The Information-Cost-Reward (ICR) framework represents a novel approach to understanding robot swarms that perform foraging. During foraging, robots need to search for worksites in an unknown environment and either perform work on them (for example, in the case of area surveillance), or collect items from the worksites and bring them to a designated location (for example, in resource collection applications).
The ICR framework relates the way in which robots obtain and share information about where work needs to be done to the swarm’s ability to use that information to perform work efficiently, given a particular task and environment.
 The ICR framework includes the following metrics:
The ICR framework includes the following metrics:
Actual reward, R: The amount of reward that the swarm got for its work. This could be a monetary value of collected resource, the number of items delivered, a customer satisfaction level reached, etc. The actual reward that a swarm is earning at a given point in time is ΔR.
Expected reward, R': Reward that the robots that know where worksites are (the "informed robots") could obtain if they did not have to travel to worksites and did not compete for the same unit of reward (they need to compete since worksites have a finite volume).
Potential reward, R*: A sum of the expected reward and the reward that could be obtained by all uninformed robots from all worksites (if the uninformed robots knew where the worksites were located).
Scouting efficiency: Related to the time of the first worksite discovery.
Information gain, I: The amount of information, i.e., the number of informed robots, that the swarm has at a given point in time.
Information gain rate, i: The maximum rate at which the information gain of a swarm can grow, i.e., the maximum rate at which the robots can find and share information
Uncertainty cost, CU: The amount of reward that the swarm is loosing due to not knowing about where worksites are located.
Displacement cost, CD: The amount fo reward that the swarm is loosing due to robots that are informed but are not located at their worksites (for example, because there is congestion around worksites or because the robots were recruited away from worksites and are traveling to them).
Displacement cost coefficient, d: Represents a ratio between the amount of CD and the decrease in CU paid at a given time. When d = 1, all robots that know about worksites are displaced from them and no reward is obtained. Intermediate values of 0 < d < 1 indicate that some robots are displaced and some are receiving reward.
Misinformation cost, CM: The amount of reward that the swarm is loosing due to robots that have incorrect information and are trying to access worksites that no longer exist (for example, because they were depleted by other robots).
When the number of worksites remains the same between two moments in time, the amount by which uncertainty cost decreases is proportional to the increase of information gain and vice versa:
ΔI(t) × r = -ΔCU(t)
where r is the amount of reward available per worksite and per robot.
The swarm cannot utilise information about worksites and obtain the full expected reward for free - it has to pay the displacement and misinformation costs associated with its control strategy. The sum of these costs explains the difference between the expected and the actual reward:
CD + CM = R' - (r/ρ)*ΔR
where ρ is the reward intake rate.
Finally, the sum of all three costs is related to the difference between the potential and the actual reward:
CU + CD + CM = R* - (r/ρ)*ΔR
In the paper, the way in which swarms with various control strategies pay various costs is explored.

A swarm is understood as a single entity that acts on its environment in order to perform some work and get reward. Reward, placed in worksites, is dispersed in the environment in a certain way, and there is a certain probability, p(W), associated with a worksite being located at a given place. Scouts play the role of the swarm’s sensors. They find new information about where worksites are, decreasing the amount of CU that the swarm pays. Since the swarm has new information about worksites, expected reward, R', is generated. When they get the new piece of information, scouts can become workers, but they can also pass that information to other members of the swarm, recruiting more workers. Discovering and sharing of information is captured by the information gain, I.
Workers act as actuators of the swarm. They can share information with each other and they do work, turning the information that they have into actual reward, R. However, there is a potential, unique to each combination of a robot control strategy, environment structure, and swarm mission, that the workers have to pay displacement cost in order to use their information. Furthermore, workers eventually cause worksites to become depleted. This can result in misinformation cost being paid by robots that are away from their worksites and therefore do not know that the worksites are depleted. At the same time, depletion of worksites decreases p(W), causing scouts to become less successful over time.
The figure above shows an example of how the various costs are paid in an environment with two worksites by a swarm where robots can let each other know where worksites are (i.e., the robots can "recruit" each other).
At the beginning, all robots are uninformed, paying the maximum amount of uncertainty cost. CU decreases when robots learn about a worksite (i.e, they "subscribe" to it), while CD increases as most of those robots are recruits that are not yet located at the worksite. When one worksite gets depleted (just after the first 1.5 hours), the total uncertainty cost decreases, since there is one less worksite that the swarm needs to know about. At the same time, robots that were subscribed to the worksite but were not located at it stop paying CD and pay misinformation cost instead. CM is paid until the robots determine that the worksite is in fact depleted and they abandon it. The task is completed when all worksites are depleted (after around 2.5 hours), and all costs fall to 0.


Date: Nov 2017
Publication: Pitonakova, L., Crowder, R. & Bullock, S. (2018). The Information-Cost-Reward framework for understanding robot swarm foraging. Swarm Intelligence, 12(1), 71-96.
A quick overview
The ICR framework includes the following metrics:Actual reward, R: The amount of reward that the swarm got for its work. This could be a monetary value of collected resource, the number of items delivered, a customer satisfaction level reached, etc. The actual reward that a swarm is earning at a given point in time is ΔR.
Expected reward, R': Reward that the robots that know where worksites are (the "informed robots") could obtain if they did not have to travel to worksites and did not compete for the same unit of reward (they need to compete since worksites have a finite volume).
Potential reward, R*: A sum of the expected reward and the reward that could be obtained by all uninformed robots from all worksites (if the uninformed robots knew where the worksites were located).
Scouting efficiency: Related to the time of the first worksite discovery.
Information gain, I: The amount of information, i.e., the number of informed robots, that the swarm has at a given point in time.
Information gain rate, i: The maximum rate at which the information gain of a swarm can grow, i.e., the maximum rate at which the robots can find and share information
Uncertainty cost, CU: The amount of reward that the swarm is loosing due to not knowing about where worksites are located.
Displacement cost, CD: The amount fo reward that the swarm is loosing due to robots that are informed but are not located at their worksites (for example, because there is congestion around worksites or because the robots were recruited away from worksites and are traveling to them).
Displacement cost coefficient, d: Represents a ratio between the amount of CD and the decrease in CU paid at a given time. When d = 1, all robots that know about worksites are displaced from them and no reward is obtained. Intermediate values of 0 < d < 1 indicate that some robots are displaced and some are receiving reward.
Misinformation cost, CM: The amount of reward that the swarm is loosing due to robots that have incorrect information and are trying to access worksites that no longer exist (for example, because they were depleted by other robots).
When the number of worksites remains the same between two moments in time, the amount by which uncertainty cost decreases is proportional to the increase of information gain and vice versa:
ΔI(t) × r = -ΔCU(t)
where r is the amount of reward available per worksite and per robot.
The swarm cannot utilise information about worksites and obtain the full expected reward for free - it has to pay the displacement and misinformation costs associated with its control strategy. The sum of these costs explains the difference between the expected and the actual reward:
CD + CM = R' - (r/ρ)*ΔR
where ρ is the reward intake rate.
Finally, the sum of all three costs is related to the difference between the potential and the actual reward:
CU + CD + CM = R* - (r/ρ)*ΔR
In the paper, the way in which swarms with various control strategies pay various costs is explored.
The ICR framework and the swarm workcycle
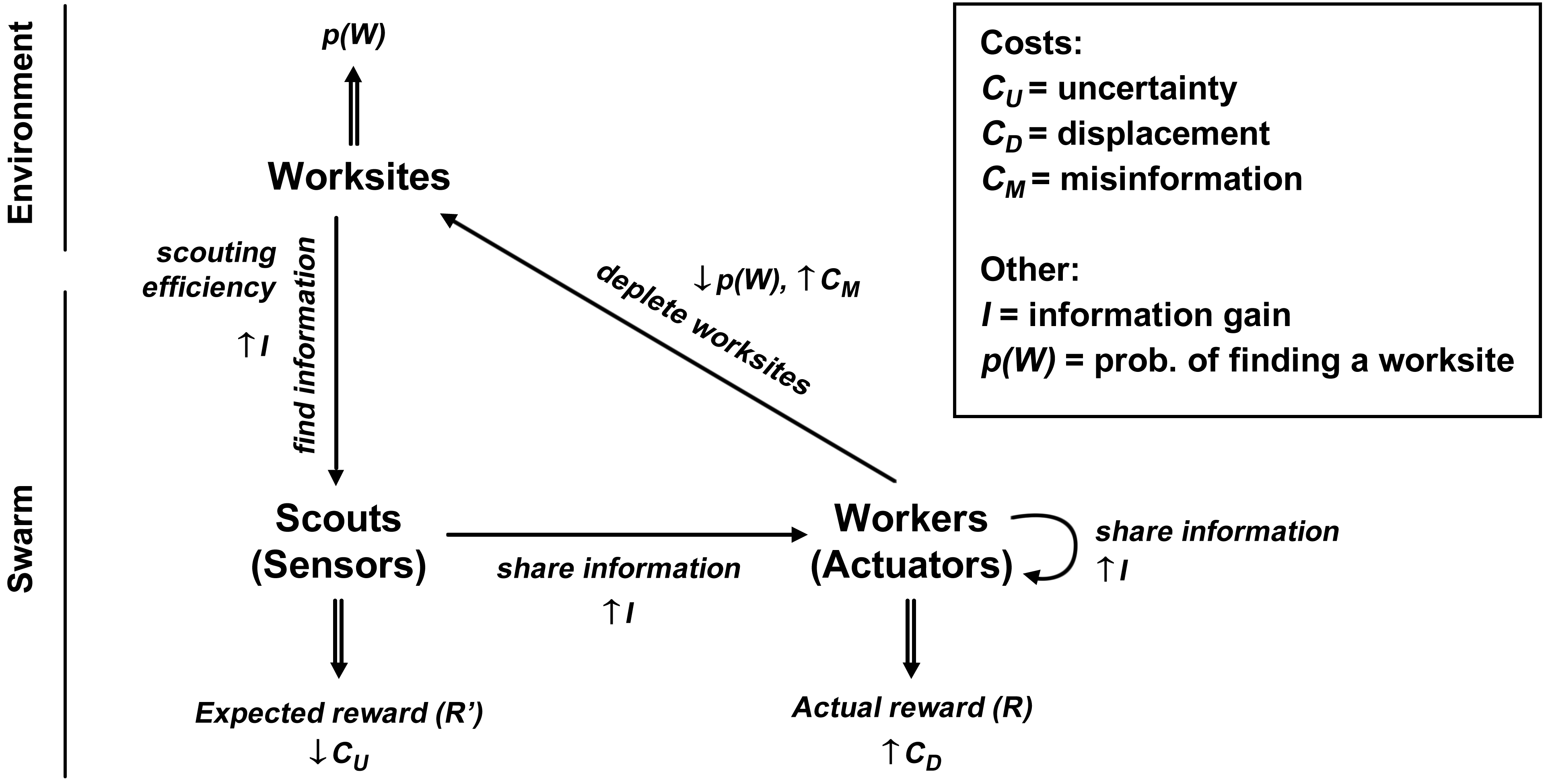
A swarm is understood as a single entity that acts on its environment in order to perform some work and get reward. Reward, placed in worksites, is dispersed in the environment in a certain way, and there is a certain probability, p(W), associated with a worksite being located at a given place. Scouts play the role of the swarm’s sensors. They find new information about where worksites are, decreasing the amount of CU that the swarm pays. Since the swarm has new information about worksites, expected reward, R', is generated. When they get the new piece of information, scouts can become workers, but they can also pass that information to other members of the swarm, recruiting more workers. Discovering and sharing of information is captured by the information gain, I.
Workers act as actuators of the swarm. They can share information with each other and they do work, turning the information that they have into actual reward, R. However, there is a potential, unique to each combination of a robot control strategy, environment structure, and swarm mission, that the workers have to pay displacement cost in order to use their information. Furthermore, workers eventually cause worksites to become depleted. This can result in misinformation cost being paid by robots that are away from their worksites and therefore do not know that the worksites are depleted. At the same time, depletion of worksites decreases p(W), causing scouts to become less successful over time.
An example

The figure above shows an example of how the various costs are paid in an environment with two worksites by a swarm where robots can let each other know where worksites are (i.e., the robots can "recruit" each other).
At the beginning, all robots are uninformed, paying the maximum amount of uncertainty cost. CU decreases when robots learn about a worksite (i.e, they "subscribe" to it), while CD increases as most of those robots are recruits that are not yet located at the worksite. When one worksite gets depleted (just after the first 1.5 hours), the total uncertainty cost decreases, since there is one less worksite that the swarm needs to know about. At the same time, robots that were subscribed to the worksite but were not located at it stop paying CD and pay misinformation cost instead. CM is paid until the robots determine that the worksite is in fact depleted and they abandon it. The task is completed when all worksites are depleted (after around 2.5 hours), and all costs fall to 0.
Applications
The ICR framework has the following applications:- It relates micro-level robot behaviour to a macro-level swarm performance by precisely identifying various costs that the robots pay
- It can aid creation of hypotheses about swarm performance in new missions
- It provides a first step towards a swarm design methodology where suitable robot behaviour can be chosen based on its effect on swarm performance in a given swarm mission



{Please enable JavaScript in order to post comments}